
Research
Jump to:
Research Replicability
Efforts to replicate past psychological study findings often fail to yield consistent results. Psychologists have conducted several large-scale multi-lab replication projects (such as the Many Labs series) to reassess the credibility of earlier findings. I am currently pursuing three lines of research to enhance our understanding of research replicability:
1. Evaluation of multisite replication study results
Psychologists are currently faced with a pressing methodological challenge: developing a framework to evaluate outcomes of replications. My doctoral work introduces a new replication success classification framework for multi-lab replication studies that goes beyond the traditional binary distinction of replication success and failure. The framework distinguishes between true and false replication successes and failures, revealing the underlying composition of observed replication results and how they are shaped by study-level factors in both the original and replication studies.
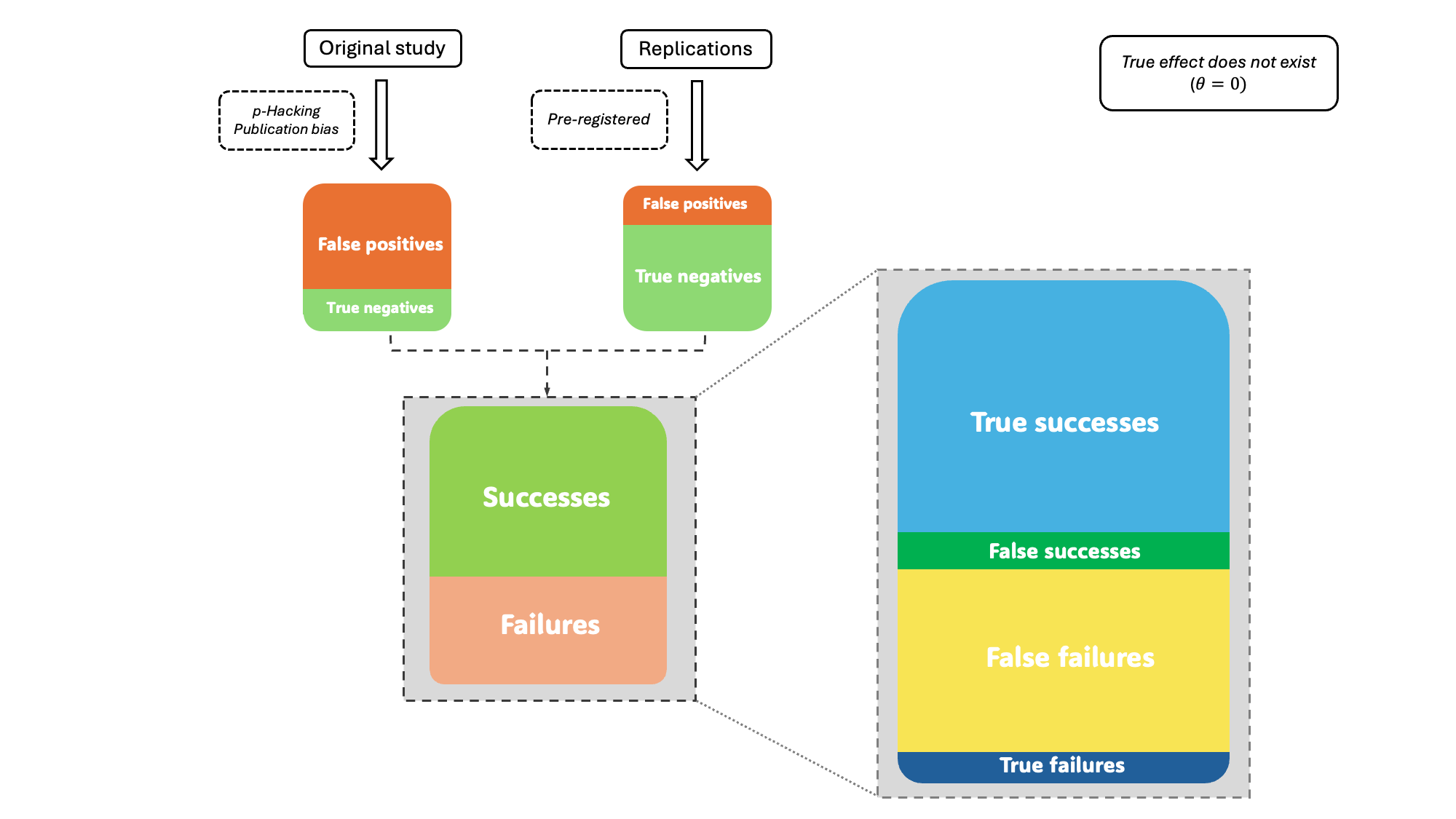
The diagram above is a conceptual illustration of how p-hacking and publication bias in original studies influence replication outcomes when the true effect does not exist. The original studies, affected by p-hacking and publication bias, are more likely to report false significant findingseven in the absence of a genuen effect. In contrast, replication studies are preregistered and unbiased, yielding results that accurately reflect the true null effect. The discrepancy between the biased originals and unbiased replications produces a larger proportion of false replication failures and a smaller proportion of true successes.
My work answers two questions: (1) When original and replication findings are consistent (replication success), how likely are they both to be correct or incorrect? and (2) Conversely, when the original and replication findings are inconsistent (replication failure), how likely are the original results to be correct and how likely are the replication results to be correct?
To answer these questions, I simulated both original studies and their direct replications. Deploying R-based simulation code on high-performance computing clusters, I created research environments with different levels of p-hacking, publication bias, and statistical power:
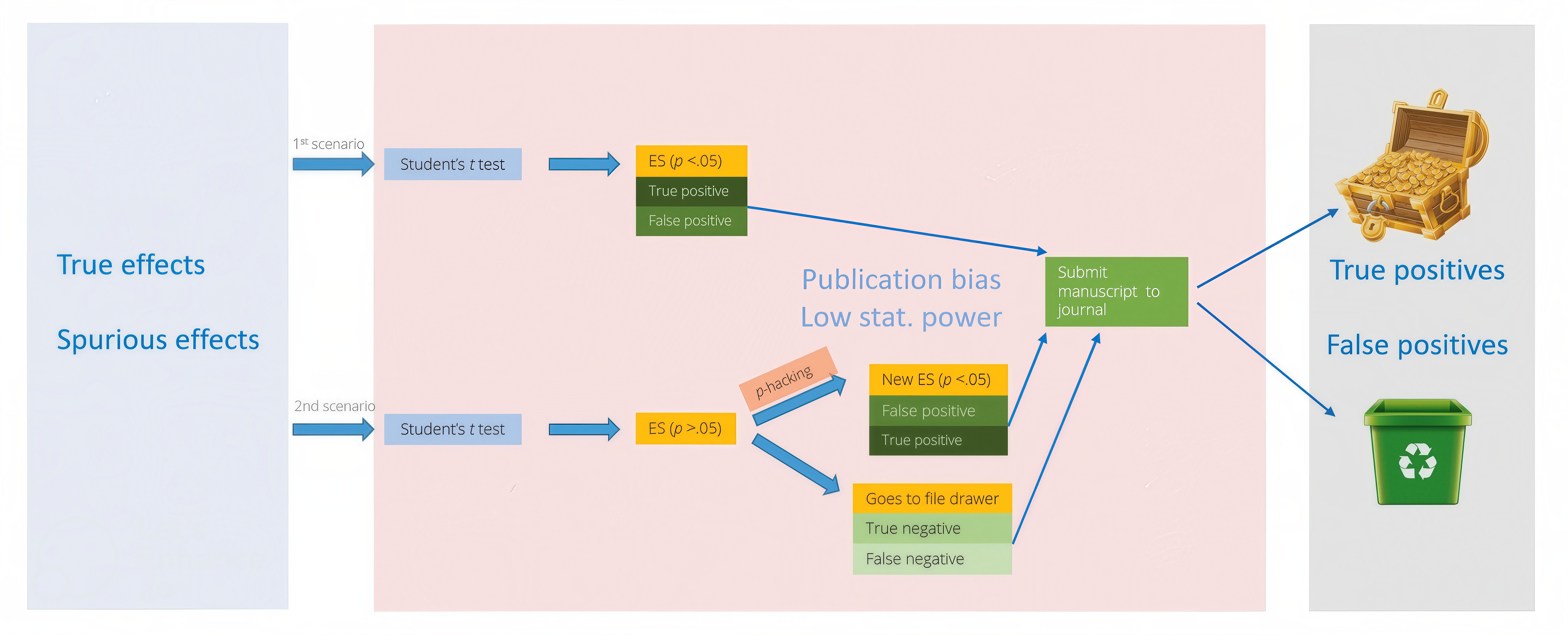
The framework illustrates how bias and methodological choices influence the underlying composition of replication outcomes. These findings provide a more nuanced understanding of replication results and offer practical guidance for designing and evaluating future large-scale replication projects to strengthen research reproducibility. An overview of the study is available in my GitHub repository.
2. Credibility of research findings in educational psychology
Statistical power plays a key role in ensuring the reliability, precision, and replicability of effect size estimation. In psychology, the average power is distressingly low—estimated at 36% with only 8% of studies deemed adequately powered. Meta-analyses synthesizing underpowered studies risk high false positive rates and inflated effect sizes. This study examines the credibility of meta-analyses published in five leading educational psychology journals by evaluating their median retrospective power. The median retrospective power of the studies included in SMD-based meta-analyses was estimated to be 31%, indicating that most of the experiment-based studies were inadequately powered. The following table shows the median retrospective power of a few selected meta-analyses included in the study. The investigated effects with a MRP larger than .5 are more likely to be true (i.e., non-spurious).
| Educational Psychology Effect | Median Retrospective Power |
|---|---|
| Activity-related Achievement Emotions | 0.94 |
| Multimedia Effect In Problem Solving | 0.74 |
| Effects of Gamification on Cognitive, Motivational, and Behavioral Learning Outcomes | 0.70 |
| Peer Interaction in Facilitating Learning | 0.51 |
| Social and Emotional Learning Interventions on Teachers’ Burnout Symptoms | 0.42 |
| Reading Interventions for Students with Reading and Behavioral Difficulties | 0.36 |
| Effects of Self-Regulated Learning Training Programs | 0.32 |
| Impact of Motivational Reading Instruction on Reading Achievement and Motivation of Students | 0.23 |
| Effectiveness of Multimedia Pedagogical Agents | 0.10 |
| … | … |
Completion of this work will raise awareness within the academic community about the prevalence of under-powered research in top-tier journals. Based on MRP, we can build a database to provide researchers with potential replication topics in psychology and their probabilities of being successfully replicated. A working paper (AERA proposal) is available here. Peer-reviewers’ feedback is available here. I presented this work in a poster session at the Modern Modeling Methods conference (view the poster).
Meta-analysis
An important application of meta-analytic methods is pooling single proportions to estimate the overall prevalence of a specific condition. In 2017 alone, 152 meta-analyses of proportions were published across various scientific disciplines, such as medicine, public health, epidemiology, etc. These meta-analyses not only guide future research but also help policymakers make informed decisions.
1. Methodological guide on conducting meta-analyses of proportions
My comprehensive tutorial offers clear, structured methodological guidance to applied researchers on how to conduct meta-analyses of proportion in the R programming environment. It presents a step-by-step workflow and a critical review on common practices that could lead to biased effect estimates or misleading conclusions.
I created a walkthrough video for this tutorial on YouTube, which has achieved 19k views, a 99% approval rating, and many positive comments. 
This tutorial has garnered significant attention from the international research community, as evidenced by more than 60,000 reads on ResearchGate and 230+ citations on Google Scholar:
- Wang, N. (2023). Conducting meta-analyses of proportions in R. Journal of Behavioral Data Science, 3(2), 1-63. Available here.
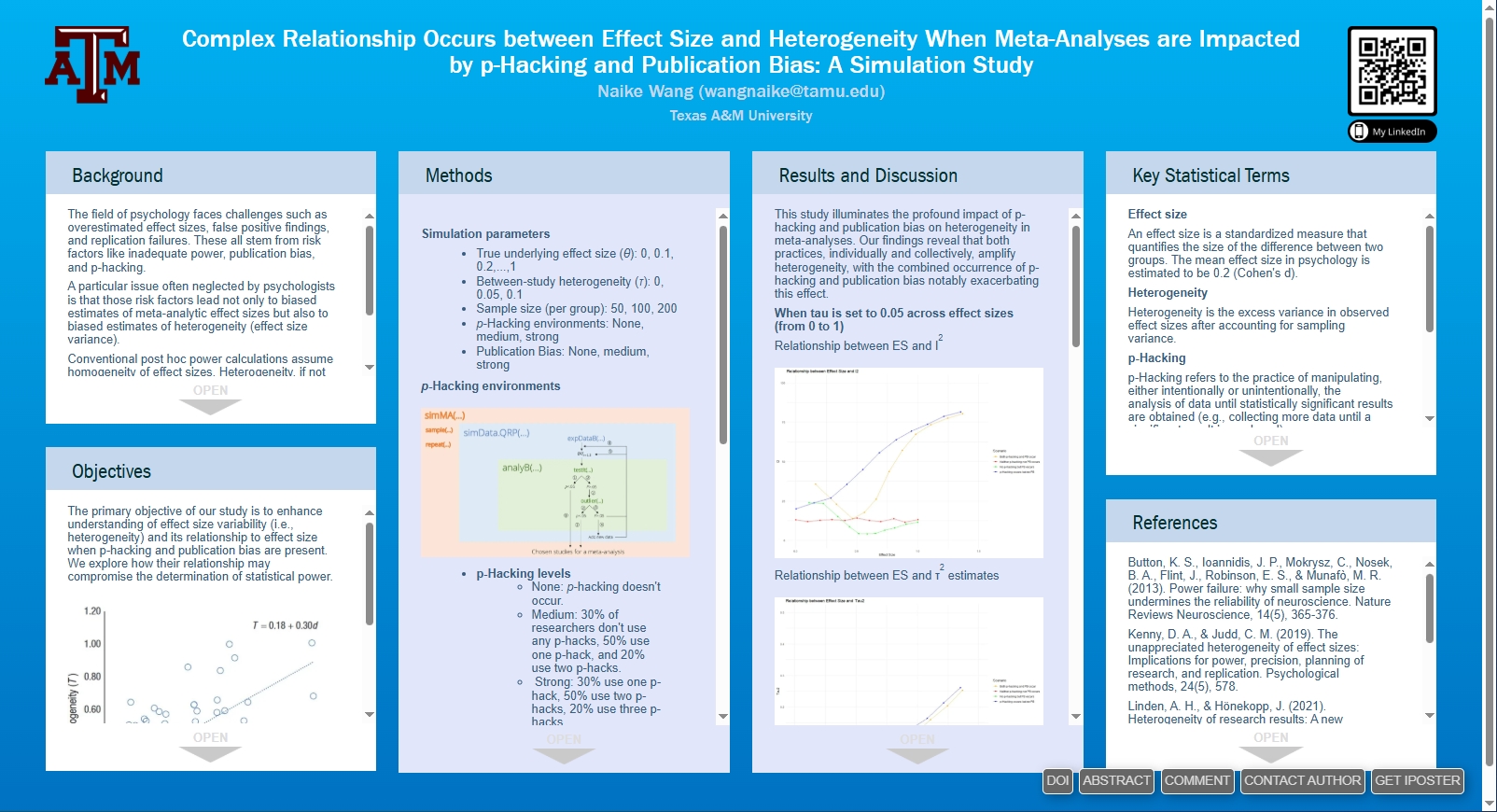
2. Effect size, heterogeneity, and power of direct replications
Effect-size variability (also known as heterogeneity), is a key methodological factor that is frequently neglected in planning the sample sizes for replication studies. My research investigates several fundamental questions regarding heterogeneity in replication studies and examines how the potentially linear relationship between effect sizes and heterogeneity may impact the statistical power of replications. Gaining a better understanding of heterogeneity is key to improving sample size planning for future multi-lab replication projects. An AERA iPoster is available here.
3. CoviPanel: A Simple, Gamified, AI-Assisted Tool for Conducting Systematic Reviews in Covidence
CoviPanel is a lightweight systematic review tool designed for researchers who need to screen large volumes of studies in Covidence. CovPanel reimagines the abstracts screening process, turinging it into a faster, more focused, and even enjoyable task.
I built CoviPanel to make the systematic review process easier for all of us. CoviPanel is free, open source, and ready for you to explore. Visit my GitHub repo, where I’ve put together clear, short, intuitive tutorials to help you get started with CoviPanel.

Key Features:
- Flexible AI-assisted screening CoviPanel integrates with #ChatGPT to offer a second opinion on each study by analyzing the title and abstract and providing a suggested decision with a concise explanation.
- Gamified rewards to stay motivated As you screen studies, you’ll level up through “academic ranks”—from a clueless Research Assistant 🤦♂️ to a distinguished Professor 🧙—via a video game–style reward system that keeps you motivated through long sessions.
- Easy, streamlined navigation CoviPanel guides you through your assigned studies in a controlled, focused sequence—no more scrolling through pages to find them!
- Multiple keyword highlighting Search for multiple keywords in titles and abstracts and highlight them simultaneously—helping you quickly spot relevant terms and rule out irrelevant studies with ease.
- Post-screening recap After each session, CoviPanel provides a clear summary of your screening activity—including time spent, decision breakdown, and interrater reliability with AI.
Generative AI for Education
My AI-related research examines the use of large language models in second-language learning, work I presented at the 22nd International Conference on Pragmatics and Language Learning in 2024. Specifically, I investigate whether models such as ChatGPT can effectively assist non-native English speakers in producing appropriate responses across diverse social contexts. I summarized this study in a 5-minute mini presentation, which you can watch here.
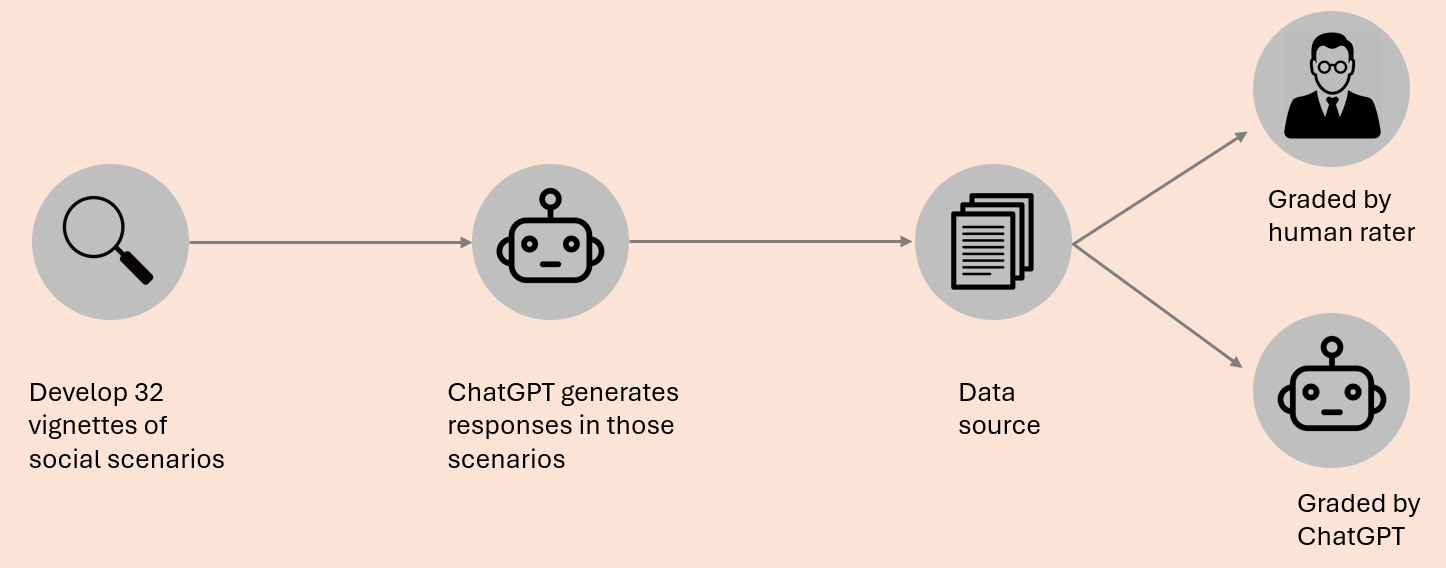
We created 32 short vignettes, each one has an everyday social scenario. We asked ChatGPT to generate responses that were either appropriate or inappropriate in those scenarios. These became our experimental materials. Then we asked both ChatGPT and human raters to grade these responses on a scale from 1 to 5 in terms of their conversational appropriateness.
The most interesting finding of this study is that in conversations involving power dynamics (e.g., when you talk to your boss), ChatGPT often struggles to find socially appropriate responses, where sensitivity to social appropriateness is essential. These findings can inform the design of AI partners that not only support learning but also foster respectful, effective communication in collaborative small-group settings.
I developed a Python-based pipeline for this project, which automated data collection across multiple ChatGPT models, reducing data processing time by 90%. The code is available here.